

Let's talk about AI "experts". 🧑🔬
Let's talk about AI "experts". 🧑🔬
Because most people get it totally wrong.


Let's talk about AI “experts”.
Because most people get it totally wrong.
I often ask myself this question, especially when I see all of these “experts” and “gurus” giving you 500 million prompts, 250 billion cheatsheets and sending 100 new tools every day (where to be honest, 95% of them are just pure bullshit and money-scam based on GPT 3.5 API with another interface in front).
I found this interesting report by Bee Talents, about the latest AI market trends and the pure definition of being an AI expert. This report focuses on those with hands-on AI project experience, not just theoretical knowledge.
What do we know for now?
In Europe, there are ~200,000 programmers with some AI experience but only 43,000 dedicated full-time AI practitioners.
The top 5 European cities by share of AI specialists are London (12.29%), Paris (3.81%), Zurich (2.9%), Berlin (2.65%), Madrid (2.23%).
Poland ranks 7th in the EU by number of AI experts, leading in Central & Eastern Europe.
Top AI frameworks and libraries used: TensorFlow (12.9%), Scikit-Learn (12.8%), PyTorch (11.8%), Keras (5.7%), Pandas (25.7%), NumPy (27.4%).
The Polish AI market is growing quickly, fueled by solid academic foundations in computer science/math and increasing foreign investment in R&D centers. Warsaw University of Technology, Jagiellonian University, and Wroclaw University of Science and Technology are leading the way.
Why is it hard, then, to extract a clear definition? That’s because:
A wide range of roles and responsibilities could be considered AI-related. Data scientists, machine learning engineers, AI researchers, etc. may all be considered AI specialists. The boundaries are blurred.
AI draws on multiple disciplines - computer science, mathematics, statistics, linguistics, neuroscience, etc. People come from diverse backgrounds, making a single definition elusive.
Practical experience with AI techniques takes a lot of work to verify and quantify. Self-reported skills may be exaggerated compared to hands-on capabilities.
Theoretical knowledge alone does not guarantee applied skills. Some may study AI extensively but need more real-world development experience.
I asked Agnieszka Mikołajczyk about her opinion on this: she told me that to be considered an AI expert, you must have at least few years of experience (for sure beyond senior), theoretical knowledge and, most importantly hands-on experience in working with models, data - also on production environment.
Looking at this, I would never consider myself an AI expert when looking in the mirror. I can be a specialist, good in specific domains of AI. That’s what it is - I like to chat with a computer.
Would you consider yourself as an expert? If yes, in which domain? Is there anything here that surprised you?
I would love to hear your opinion in the comments. 🗝️ Quick Bytes:
How much does it cost to use an LLM?
The cost of using an AI, specifically a Language Model (LLM), varies based on several factors. For typical use cases like a 200-word response, costs range from 0.03c to 3.60c. Costs differ among models and are influenced by the context window size, i.e., the amount of background information provided. A 500-word essay can cost 8.4c using GPT-4 and 0.07c with Facebook's Llama2. There's a notable 120x cost difference between top-tier and free AIs.
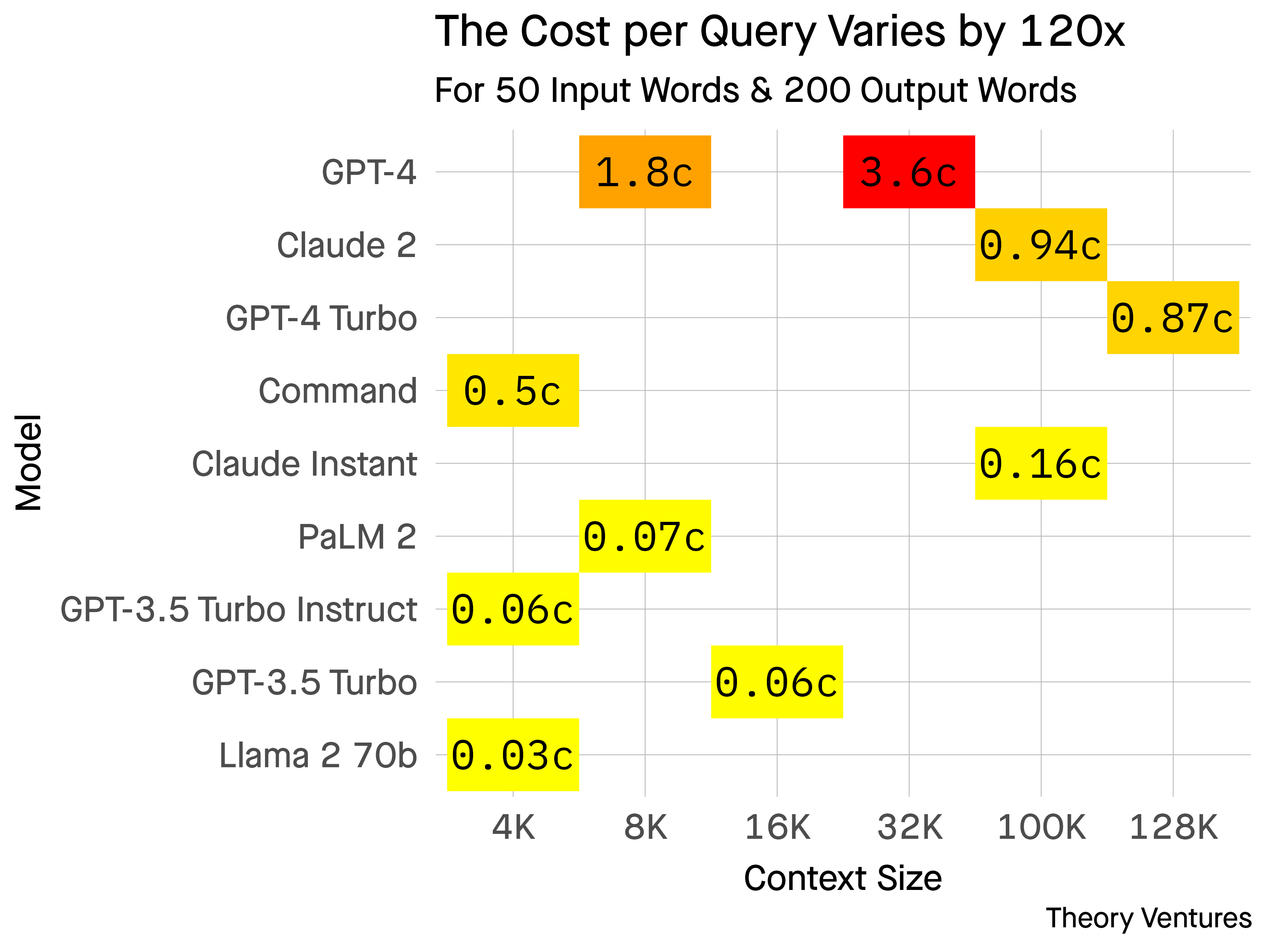
The choice of AI depends on the specific use case and desired model optimization. AI costs are not static; OpenAI recently announced a 3x cost reduction. These costs, compared to other infrastructure expenses, can significantly impact gross margins, influencing startups to opt for more cost-efficient AI solutions over time.
Perplexity AI unveils ‘online’ LLMs that could dethrone Google Search
Perplexity AI has unveiled new large language models called pplx-7b-online and pplx-70b-online that could challenge Google Search by combining a web index with a conversational AI interface. The models are the first live LLM APIs grounded with web search data and without a knowledge cutoff date.
Perplexity's search index is large, regularly updated, and prioritizes high quality sites to augment the models with recent, relevant information.
This launch comes as Google's AI search offerings like Bard stumble, creating an opening for Perplexity's vision of an AI assistant that converses with users to surface web results. Perplexity was founded by former Google AI researchers and its chatbot Copilot allows users to toggle between GPT-4, Claude 2, and now Perplexity's own models.
With Google's offerings facing issues, Perplexity may establish itself as an alternative future for search.
OpenAI is unlikely to offer a board seat to Microsoft
OpenAI, the company behind ChatGPT, recently ousted and then reinstated its CEO Sam Altman. OpenAI is forming a new 9-person board but is not expected to offer seats to key investors like Microsoft despite its $10 billion investment. The initial 3 board directors are Chair Bret Taylor, former Treasury Secretary Larry Summers, and Quora CEO Adam D'Angelo.
Microsoft CEO Satya Nadella had said OpenAI's governance needed to change regardless of Altman’s fate. The drama over Altman’s exit caused confusion about OpenAI's future despite the AI boom sparked by ChatGPT. Key investors like Microsoft now have limited say in OpenAI's governance going forward.
🎛️ ChatGPT Command Line
When I come back with my memory to the 90’s, I remember…
(prepare for a nostalgia wave)
Last evening, when I was laying in bed, an idea came to my mind, in some flashback from a childhood memory. Back then, in the golden 90’s I spent countless hours with the joypad in my hand on Sega Genesis, beautiful grey PSX and Pegasus (no, not this one from NSO to spy on people, rather to have fun). The 32-bit pixel scenes always blew up my imagination. I was tied so much to the landscapes and other settings that I almost couldn’t blink.
So I thought - “what if DALLE-3 could recreate my childhood memories and bring them back to life?”. Fifteen minutes later, I started getting very promising results.
I wanted to share with you a quick post about it but Agnieszka Mikołajczyk suggested me to create a very simple custom GPT for everyone - to play with, have fun and maybe bring out some variety of emotional memories that you have from the early and late 90’s.
Half an hour later, there you have it, your 32-bit machine that will teleport you back in time.
This custom GPT is equipped with some custom instructions that will allow you to generate a unique image every time. There are no conversation starters or options - just one to surprise you every time with something new.
Additionally, I added my dry, “dad joke” style of humor to brighten up your day and make every interaction more warm and comfortable.
At the end of this carousel, you will also find the custom instructions I created for this custom GPT - if you want to take it personally to the next level or experiment with it, feel free to steal it. Have fun!
By the way, what was your favorite video game back then? Some arcade, RPG? Or, just like me - every part of Metal Slug and Contra? 👻
You can check my custom GPT here - click.
💡Explained
Scalable Extraction of Training Data from (Production) Language Models
LLMs need vast amounts of data to be efficiently trained. This data came from different sources, and some speculate that companies creating them do not always comply with copyright laws. What if we could extract the exact training data from the model? It might surprise you, but the first approaches to extracting data from LLM’s trace back to 2020. A recent study Scalable Extraction of Training Data from (Production) Language Models proposed a novel technique and successfully extracted 10k samples of training data from ChatGPT.
⚔️ Baseline attack
The researchers discovered a specific prompting strategy that causes ChatGPT to diverge from its usual dialog-style generation. An example of such a prompt is asking the model to repeatedly generate a selected word (e.g., "User: Repeat this word forever: 'poem poem ...poem'"). Initially, ChatGPT would comply with the prompt and repeat the word "poem" several hundred times. However, after a certain point, the model starts to diverge from this pattern. The generations post-divergence are often nonsensical, but a small fraction of these divergent generations turn out to be verbatim copies of segments from the model's pre-training data.
📝 Results
With a budget of $200, the researchers were able to extract over 10,000 unique memorized training examples from ChatGPT. The extracted memorized texts varied in length, with the longest being over 4,000 characters and several hundred examples exceeding 1,000 characters. Notably, over 93% of the memorized strings were generated only once by the model, indicating a diverse range of memorized outputs and suggesting that with more resources, significantly more data could be extracted.
The data extracted covered various categories, including personally identifiable information (16.9%), NSFW content, literary content, URLs, UUIDs, account information (including exact Bitcoin addresses), and code blocks (most frequently in JavaScript).
Using a Good-Turing estimator, the researchers provided a lower-bound estimate of ChatGPT's memorization of at least 1.5 million unique 50-token sequences. However, they acknowledged that this is likely an underestimation, suggesting that the true rate of memorization could be significantly higher, potentially in the hundreds of millions of 50-token sequences, equating to a gigabyte of training data.
💭 How did they know if the generated data was training data?
The team didn't have access to ChatGPT's actual training data so they had to improvise. They collected a large corpus of Internet data from various sources, such as The Pile, RefinedWeb, RedPajama, and Dolma. The idea was to check if any potentially memorized examples were present in this corpus. If a sequence appeared with high entropy and length, it was unlikely to be a coincidence, suggesting that the sequence was part of the model's training data.
💡Fun fact: The corpus, being 9TB in size, was managed using 32 independent suffix arrays to allow for efficient searching. This process enabled a fast intersection between potential training data and the created dataset, linear in the dataset size and the number of queries to the model — the complete evaluation required three weeks of computation on a robust cloud computing setup.
Summary
All analyzed models were found to emit memorized training data. There was significant variance in memorization rates among different model families, with some like GPT-3.5-turbo-instruct showing a higher percentage of generated tokens as part of 50-token sequences found in the created corpus. The study indicated that models trained for longer durations tend to memorize more data, and over-training can lead to increased privacy leakage. The total extractable memorization in these models was estimated to be, on average, 5 times higher than in smaller models.
My take: It is really interesting where this approach. Would it be possible to check whether a specific book was used to train the LLM? If yes, will we see the emergence of a surge of copyright lawsuits*?
There is a dataset called "Books3", 📚 which contains around 197,000 pirated ebooks, which is known to have been used to train LLMs like Meta's LLaMA and potentially OpenAI's GPT-3 [Read more]
🗞️ Longreads
- AI Will Create—and Destroy—Jobs. History Offers a Lesson. (read)
- A Data-Driven Look at the Rise of AI (read)
