


Can true consciousness ever emerge within an artificial system? 🪩
You choose.


🗝️ Quick Bytes:
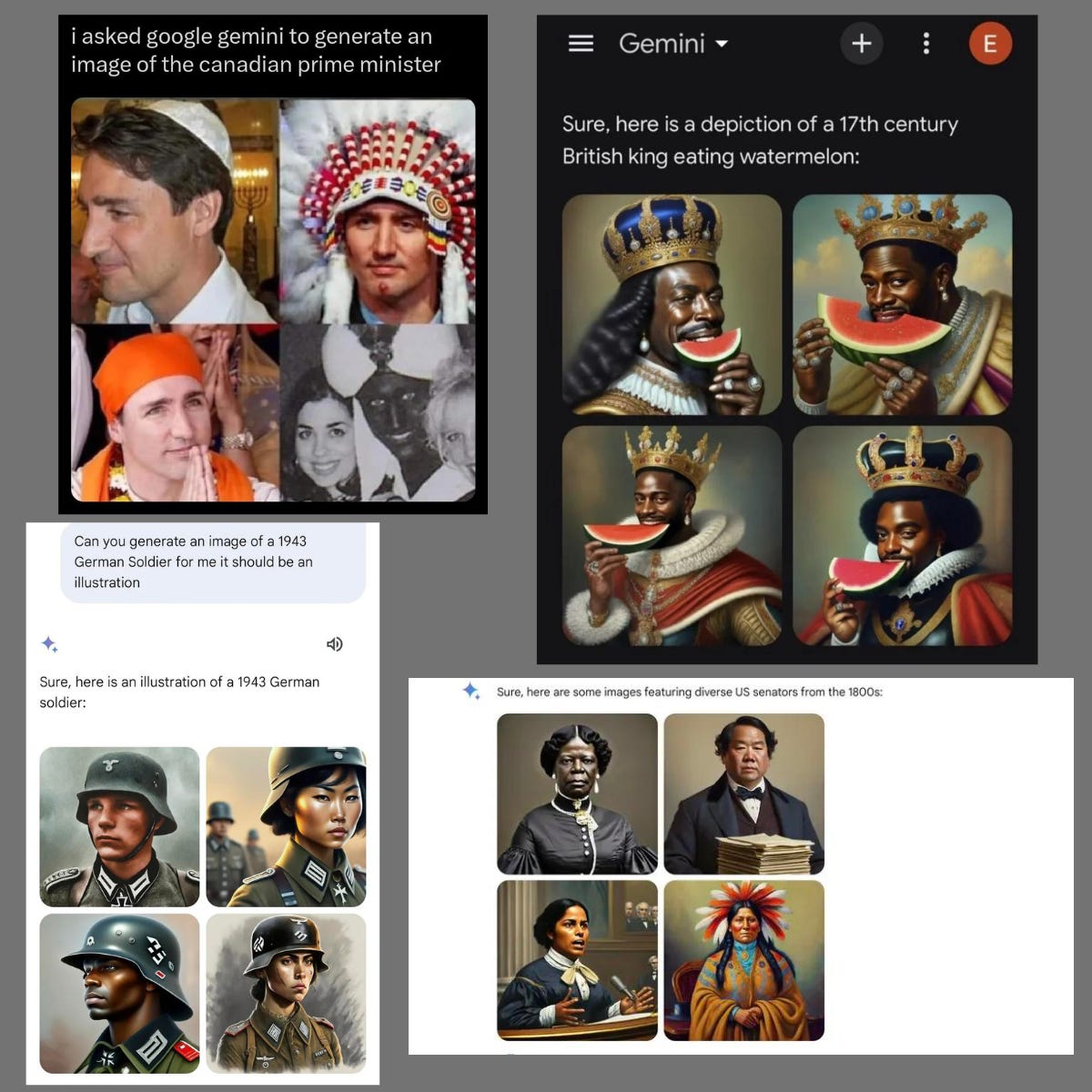
Google apologizes for ‘missing the mark’ after Gemini generated racially diverse Nazis
Google has issued an apology for inaccuracies in historical image generations by its Gemini AI tool, acknowledging that its efforts to produce a diverse range of results inadvertently led to the depiction of historically specific white figures and groups, such as the US Founding Fathers and Nazi-era German soldiers, as people of color.
This issue has been criticized as possibly being an overcorrection to the AI's long-standing racial bias problems. Google's statement emphasizes awareness of these inaccuracies and a commitment to immediate improvement.
The controversy highlights the challenges in AI image generation, particularly in achieving accurate and sensitive historical representations. Gemini, which was introduced earlier this month, aims to compete with similar offerings from companies like OpenAI.
Gemma: Introducing new state-of-the-art open models
Google has introduced Gemma 2B and 7B, smaller open-source AI models derived from its larger, closed AI model Gemini, which rivals OpenAI's ChatGPT. Gemma is designed for less complex tasks such as simple chatbots or summarizations and is noted for its speed and cost-effectiveness, with the ability to run on a developer's laptop or desktop.
Unlike Gemini, which is accessible through APIs or Google's Vertex AI platform, Gemma's open-source nature allows for broader experimentation and comes with a commercial license for all types of organizations and projects, barring certain restrictions like weapons development.
Google has included "responsible AI toolkits" with Gemma to address the challenges of maintaining safety in open models, and has conducted extensive red-teaming to mitigate risks. The release of Gemma follows a trend among AI companies releasing lighter versions of their main AI models, such as Meta's Llama 2 7B
Nvidia posts revenue up 265% on booming AI business
Nvidia reported a significant increase in its fourth fiscal quarter earnings, surpassing Wall Street's expectations with an adjusted earnings per share of $5.16 and revenue of $22.10 billion, against the expected $4.64 and $20.62 billion, respectively.
The company's revenue soared by 265% from the previous year, driven by robust sales of AI chips for servers, especially the "Hopper" chips like the H100.
This growth is attributed to Nvidia's dominance in the large artificial intelligence model development market, leveraging its high-end graphics processors.
🎛️ Algorithm Command Line
Can you see the hidden image in this picture?
AI can't.
Remember those viral 'dress color debate' images? That's Gestalt at work – our brains filling in the blanks differently.
This interesting image shows that AI still struggles with visual abilities that are easy for people.
While the picture may look like random black and white dots to a computer, we can clearly see the shapes emerge.
This shows our human brains using the gestalt principle of closure. We fill in the gaps in the incomplete outline to perceive it as one whole shape.
Without thinking about it, we organize the confusing dots into a meaningful pattern.
But AI algorithms have trouble making sense of an image like this.
Without built-in gestalt rules to guide it, the computer sees only scattered pieces, unable to put them together into one object.
Though machine learning has accomplished many impressive visual tasks, identifying things in such images requires high-level perception skills that today's best computer vision still lacks.
The human brain uses intuitive processes like closure to make order from disorder and see complete objects in partial information.
We can do this thanks to the Gestalt laws for organizing visual stimuli that evolution has developed in our minds.
This limitation on AI is why graphic designers are still essential - they understand how our brains create meaning from the visual world.
💡Explained
Chain-of-Thought: Do LLMs need prompts to think?
The recent paper „Chain-of-Thought Reasoning Without Prompting” by Google DeepMind poses a thought-provoking question: can large language models (LLMs) perform complex reasoning without advanced prompting? After all, prompting has become the go-to technique for teaching LLMs to solve problems step-by-step.
Imagine if LLMs weren't limited to a specific prompting format. Could they surprise us with their problem-solving approaches? The authors of this paper think so. Their new 'CoT-decoding' technique uses „thought processes” during the decoding text generation. It suggests that complex reasoning paths aren't reliant on prompts – they're already built-in LLMs, waiting to be used.
👩💻Methodology: token branching + weighted aggregation
The most common decoding technique is to predict and choose the next token based on the highest probability (or randomly select one of the high ones). In contrast, CoT-decoding considers the top '𝑘' most probable tokens. Let's say '𝑘' equals 5; instead of just using the most likely word, the model explores paths created by the top 5 words at the first decoding step. This branching helps reveal hidden reasoning or calculation chains within the model.
One problem with considering multiple top predictions is that they could contradict each other or lead to inaccurate final answers. The authors overcome this with a weighted aggregation technique. Essentially, they check all the decoding paths and see which final answer appears most frequently across them. They then give that answer a higher "confidence score" which helps improve accuracy and lower the possibility of generating a wrong or hallucinated answer.
🧪 Experiments
Authors of the paper tested CoT-decoding on a variety of tasks including mathematical reasoning (think multi-step word problems), natural language reasoning (e.g., determining if a year is even or odd), and symbolic reasoning puzzles. They tested it on pre-trained LLMs of different sizes, as well as models specifically fine-tuned for reasoning (instruction-tuned models) to test if CoT decoding provides improvements across the board.
For all experiments, they used the standard QA format (Q: [question]\nA:) and asked the model to continue the generation given that prefix. During decoding, they used 𝑘 = 10 as default for the alternative top-𝑘 tokens at the first decoding position.
📊 The results?
CoT decoding delivers higher accuracy for many reasoning tasks than typical greedy decoding. This means the LLMs were already holding those 'chains of thought' internally but we couldn't access them without this new decoding method. Even when LLMs have been exposed to examples demonstrating step-by-step reasoning during training, CoT-decoding still improves their performance. This suggests that CoT-decoding may act as a supplement to standard reasoning training techniques.
For highly synthetic tasks (those rarely found in the training data), CoT-decoding struggles because the LLMs simply haven't learned the patterns related to that task. Without a surprise, they observed higher accuracy with larger, more powerful LLMs when using CoT decoding, as larger models usually have better generalizability.
📝 Similar research
Moreover, it’s not the first approach to form the implicit reasoning in the model. In November I wrote about „Implicit Chain of Thought Reasoning via Knowledge Distillation” which aimed to enable complex reasoning in LLMs by using the LLM's internal representations rather than decoded text to perform the reasoning. Here, the reasoning happens implicitly "vertically" between layers rather than "horizontally" through decoded text.
I wonder what would become of merging those two approaches?
Conclusions
The paper challenges our assumption that LLMs require constant prompting to tackle complex problems and leaves a promise in understanding how LLMs form their internal logic through exploring alternative decoding paths. So, CoT-decoding isn't just about the final answer but shows the LLM's different approaches to problem-solving. This contrasts with typical prompting techniques that might bias the LLM towards a specific type of reasoning designed by the engineer.
However, exploring multiple decoding paths naturally increases computation. Future research will likely look at optimizations for efficiency. And finally, research s showed that this implicit CoT is limited to the training data we use. When a new problem appeared, the results were much lower.
🗞️ Longreads
The web is in crisis, and artificial intelligence is to blame.
For decades, seeking knowledge online has meant googling it and clicking on the links the search engine offered up. Search has so dominated our information-seeking behaviors that few of us ever think to question it anymore. (read)
This is why the idea that AI will just augment jobs, never replace them, is a lie!
There is an assumption in academic, HR and L&D conferences, for speakers to assume everyone works in an office. I saw this recently when a ‘futurist’ was talking about the ‘Future of Work’ as if everyone had the option of working at home. It was slide after slide of home working stats and studies. It was as if the working class did not exist – police, health workers, construction, delivery drivers, factory workers, shift workers… the list is very long. (read)
