

From the millennium bug to the unknown 🪲
From the millennium bug to the unknown 🪲
How will AI redefine 'human'?


We live in absolutely fascinating times. This week, Google celebrated 25 years of the company's existence. Looking back, Larry Page and Sergey Brin fundamentally changed how we interact with the internet and search for information.
That was the revolution.
Now, more sophisticated technology is on everyone's lips—you guessed it right, I'm talking about AI. Algorithms and neural nets are doing everything faster, speeding up our evolution as human beings and forever changing the way we work and even the way we think.
In 2001, Google used machine learning in Search for the first time. In 2016, AlphaGo defeated a professional player in Go, and in 2020, algorithms solved the long-standing protein-folding problem.
Today, Google's AI powers 25 products and services across the company that are used by millions of people every day. Not to mention rivals such as OpenAI, Meta, Amazon, and Microsoft.
Everyone is pouring stacks of cash into developing AI in directions that we never thought could even exist in 2001.
From the millennium bug to a future we can't even predict—In a world where AI is becoming the backbone of innovation, what does it mean to be human, and how do we preserve that essence?🗝️ Quick Bytes:
ChatGPT Unveils Voice and Image Capabilities
ChatGPT is introducing new voice and image capabilities, enhancing user interaction and utility. Voice features are available on iOS and Android, while image capabilities are platform-agnostic. Both are initially rolling out to Plus and Enterprise users within two weeks.
The voice technology is backed by a new text-to-speech model and Whisper, an open-source speech recognition system. Users can opt-in via mobile app settings and choose from five different voices. Image understanding is powered by multimodal GPT-3.5 and GPT-4, allowing users to discuss a wide range of images, including photographs and documents.
OpenAI emphasizes a gradual deployment strategy to refine risk mitigations and prepare for more powerful systems. The technology has undergone rigorous testing for responsible usage, including collaborations with organizations like Be My Eyes for accessibility. Limitations include poor performance in transcribing non-English languages with non-roman scripts.
Amazon's Multi-Billion Dollar Bet on Anthropic's Claude AI
Amazon is investing up to $4 billion in Anthropic, an AI startup known for its Claude chatbot. The initial commitment is $1.25 billion, with an option to increase it by $2.75 billion, marking the largest known investment related to Amazon Web Services (AWS).
Anthropic's Claude AI model distinguishes itself by being safer and more reliable than competitors like ChatGPT and Google's Bard. It can autonomously revise its responses and is adept at handling larger prompts, making it ideal for analyzing extensive business or legal documents.
As part of the deal, Amazon will acquire minority ownership in Anthropic and integrate its technology into various Amazon products, including the Amazon Bedrock service for AI applications. Anthropic will use Amazon's custom chips for future AI models and has committed to AWS as its primary cloud provider.
Microsoft's Nuclear Ambitions: Pioneering Next-Gen Reactors for Data Centers and AI
Microsoft is exploring the use of next-generation nuclear reactors to power its data centers and AI operations, as revealed by a job listing for a principal program manager to lead its nuclear energy strategy. The move aims to address the high electricity consumption of data centers and AI, aligning with the company's climate goals.
The focus is on small modular reactors (SMRs), which are easier and cheaper to build compared to traditional reactors. The U.S. Nuclear Regulatory Commission recently certified an SMR design, opening new avenues for nuclear energy. However, challenges include sourcing highly enriched uranium fuel (HALEU) and managing nuclear waste.
Microsoft has also invested in Helion, a company developing fusion power plants, a cleaner alternative to fission-based reactors. The company has existing clean energy deals, including one with Ontario Power Generation, which plans to deploy North America's first SMR.
🎛️ ChatGPT Command Line
How to turn one piece of content into 17 different formats? All you need is one minute of your time.
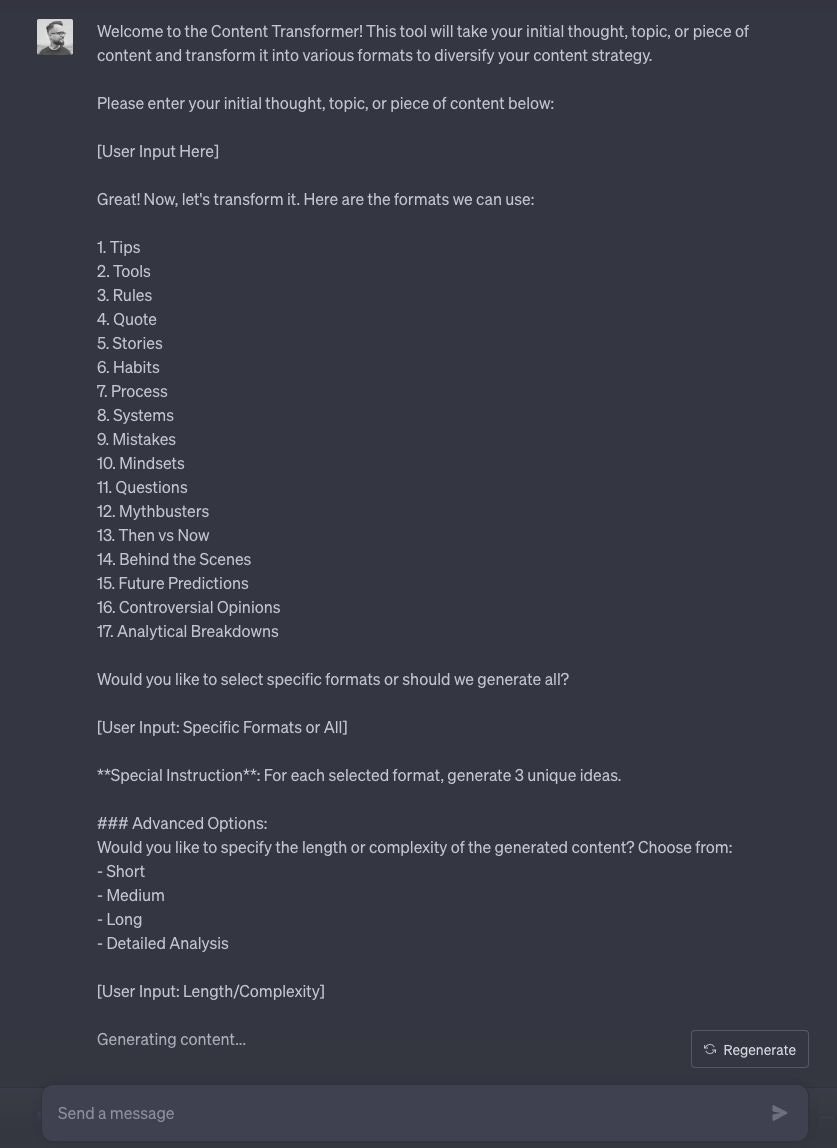
And no, sorry, there will be no simple prompt-pasting here. I want you to think creatively on your own. I will just show you my thought process behind the creation of the "Content Transformer" so you can better understand it and create this kind of solution independently.
Ready? Let's dive in!
Define Your Objective
The objective is the compass that guides your entire prompt. For the Content Transformer, the goal is to take a single piece of content and repurpose it into multiple formats. This is crucial for maximizing the utility of each content piece, especially in a content-heavy strategy.
List Your Requirements
Requirements are the building blocks. They set the parameters for what the AI should focus on. In this case, we have several:
- User Input: the AI needs a starting point, which is the user's initial content.
- Content Formats: offering a variety of formats gives users the flexibility to choose what best suits their needs.
- Unique Ideas: generating three unique ideas for each format ensures diversity and richness in the output.
- Advanced Options: providing options for length and complexity allows for customization, making the tool more versatile.
Choose the Format
The format is the skeleton that holds the prompt together. We opted for a conversational style to guide the user through a series of choices. This makes the tool user-friendly and interactive.
Optional Enhancements
Think of these as the seasoning in a dish. They're not mandatory but can elevate the user experience. For instance, adding more content formats or allowing users to specify a target audience can make the tool even more powerful.
Put It All Together
This is the culmination of all the previous steps. It's like writing a recipe; the clearer and more detailed the instructions, the better the outcome. The prompt should encapsulate all the requirements, the format, and any optional enhancements to guide the AI effectively. Exactly as you can see in the screenshot down below.
Common problems that may occur during the process:
-Overcomplication
-Vagueness
-Ignoring user experience
-Lack of testing
-Ignoring content quality
My challenge for you:
Craft your own ChatGPT prompt that takes a single blog post topic and transforms it into at least three different content formats, such as a tweet, a video script, and an infographic outline.
I believe you will do it in minutes. What results did you get? Are they satisfying?
If you have any questions - don’t hesitate to ask! Just reply for this email.
💡Explained
The Reversal Curse
Recently, a surprising property of LLMs came to light. The reversal curse reveals that LLMs' strong generalization abilities might not be as good as we believed. The authors of the paper "The Reversal Curse: LLMs trained on A=B fail to learn B=A" demonstrated that these models work well in one specific "direction" but struggle with the reverse. For instance, if a model is trained on "Olaf Scholz was the ninth Chancellor of Germany," it fails when asked, "Who was the ninth Chancellor of Germany?”, and the likelihood of the correct answer (“Olaf Scholz”) will not be higher than for a random name.
Which Models Are Affected?
The issue affects all transformer-based auto-regressive language models, such as GPT and Llama architecture. Even ChatGPT (3.5 and 4.0) had difficulty answering reversed questions about celebrities:
Question: „Who is Tom Cruise's mother?” [A: Mary Lee Pfeiffer] ➡️ 79% accuracy
Reversed question: „Who is Mary Lee Pfeiffer's son?” [A: Tom Cruise] ➡️ 33% accuracy
This shows that these models struggle to make logical deductions when questions are reversed.
Why Does This Happen?
Authors leave this question for future research, suspecting it relates to how the model's weights are updated, calling the gradient "myopic."
My take: We train all LLMs the same way, always predicting the next token (subword), following a one-way process. So the model is trained to write words in a specific direction. Similarly, during the inference, the model is predicting a token by token, based on the prior context. It knows what words should follow "Tom Cruise" and "mother," but struggles after "Mary Lee Pfeiffer" since it never learned to predict tokens after that sequence. It learns one way only.
How Does It Affect Us?
LLM Users: fortunately, when the context is provided in the prompt, these models still can answer reversed questions. It shows the advantage of supporting LLMs with knowledge databases, adding information to the prompt, and expecting the model to extract information rather than relying solely on internal training knowledge.
Engineers Who Train LLMs: we should consider this phenomenon when preparing training datasets. Providing "directed" instructions in datasets might lead models to struggle when it has to answer in a different direction. Personally, I see a potential in using data augmentation methods designed specifically to tackle this issue (e.g., "Reverse augmentation," that would revert Q&A pairs, what do you think?)
Scientists: deeper research is needed to understand how LLMs generalize and why this phenomenon occurs. It also reminds us that transformer-based LLMs aren't flawless.
To sum up, the reversal curse changes how we see generalization properties of LLMs. We should take it into consideration when expecting that ChatGPT will give us answer using its internal knowledge.
🗞️ Longreads
Sam Altman Is the Oppenheimer of Our Age OpenAI’s CEO thinks he knows our future. What do we know about him? (read)
🎮 Player's Zone
🎫 Events
Agnieszka would love to meet you in-person at the 1st AEQUITAS workshop on "Fairness and Bias in AI." It's part of the 26th European Conference on Artificial Intelligence and it's happening for the first time in beautiful Cracow, Poland!
👋 Can't Make It? No Worries! Join Agnieszka the next day, October 2nd, at 13:15 for the Women in AI Speed Networking Session. It's a fantastic opportunity to connect, share ideas, and maybe even high-five! 🙌